Chatbots fail to ease patient decisional conflict
A new clinical trial reveals that giving patients ChatGPT before or after their specialist visits does not reduce their anxiety or help them make better treatment decisions.

A new clinical trial reveals that giving patients ChatGPT before or after their specialist visits does not reduce their anxiety or help them make better treatment decisions.
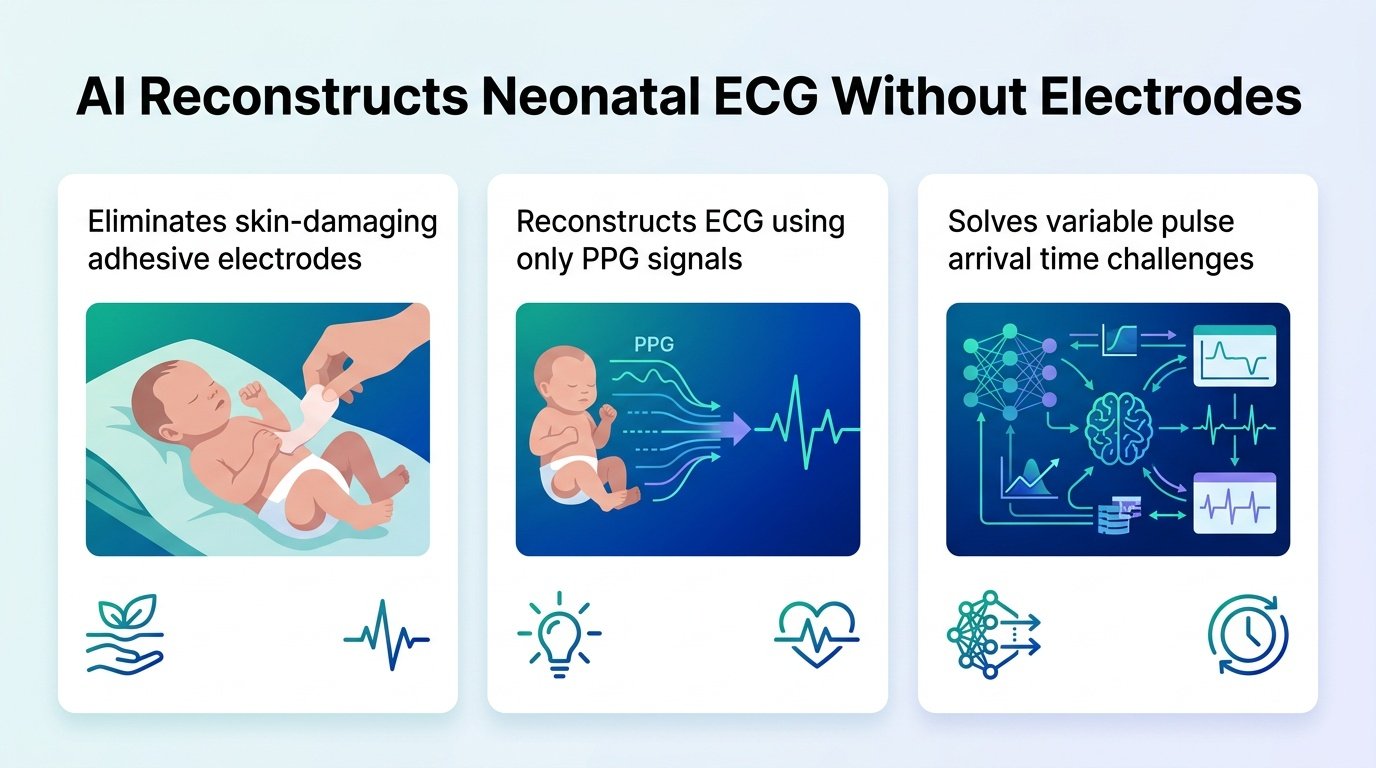
A new AI model reconstructs missing neonatal heart signals using light-based sensors, bypassing the need for irritating skin adhesives in intensive care.
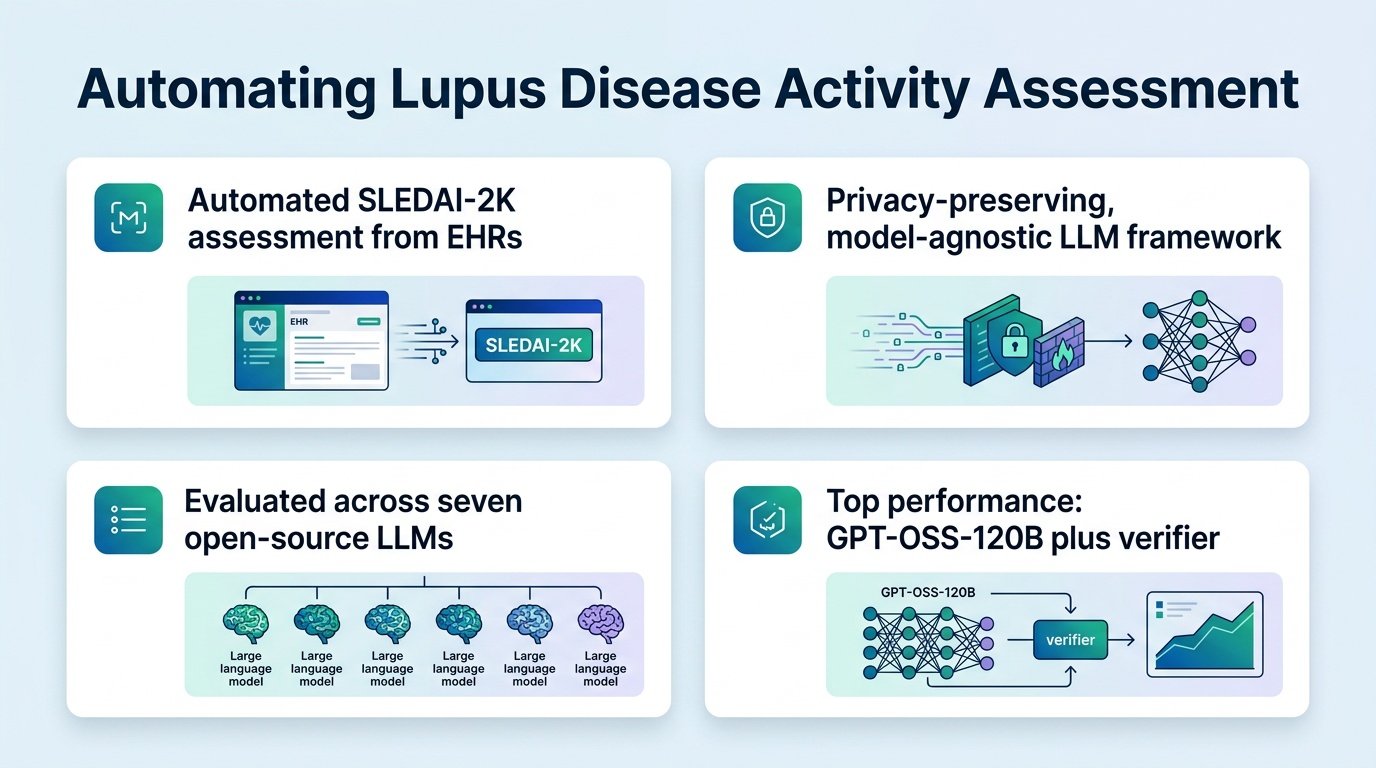
Automating lupus tracking with open-source language models could finally bring standardized disease monitoring to busy clinics.
A new clinical benchmark reveals that large language models fail frontline health workers unless their queries are translated into English first.

A new pilot shows that automating clinical notes saves little time but dramatically lowers cognitive fatigue.
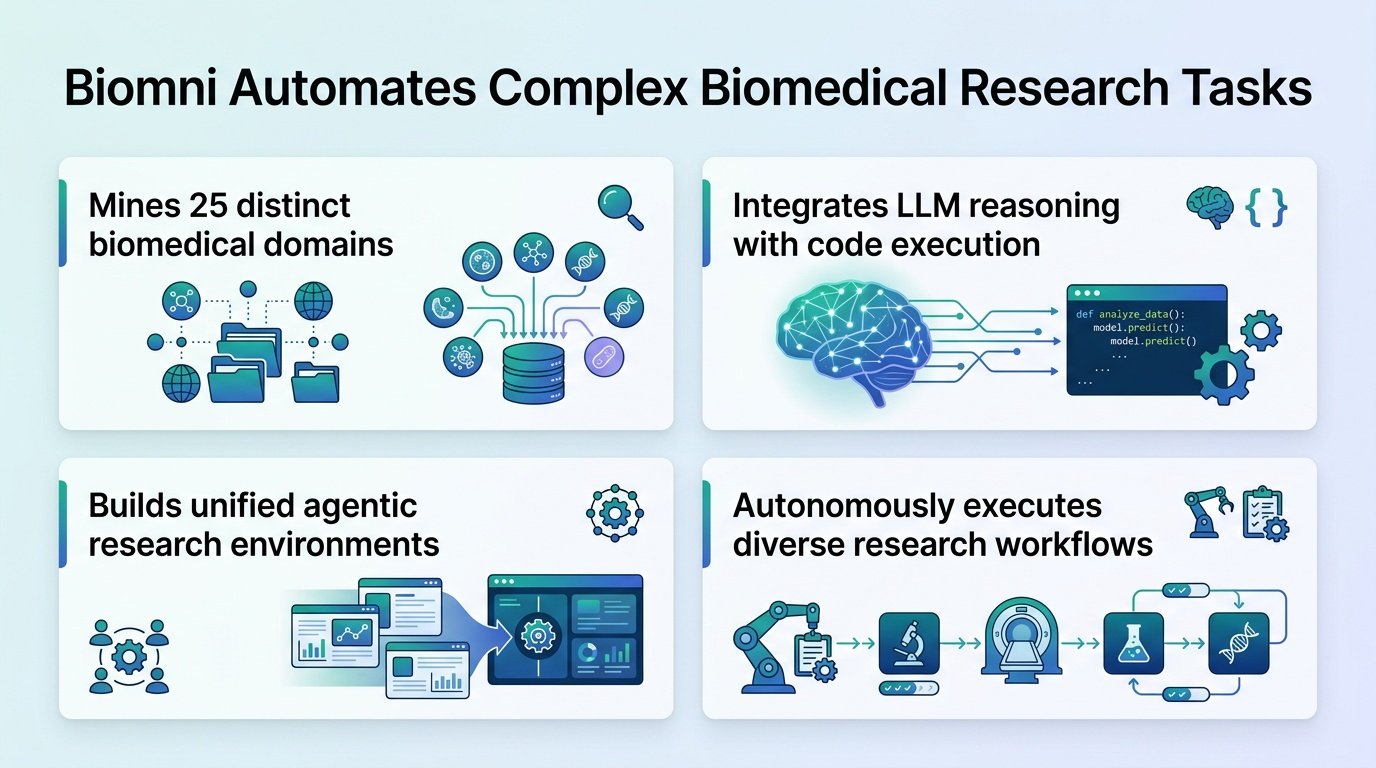
A new AI agent named Biomni can design and run its own lab experiments, shifting the bottleneck of medical discovery from human labor to machine execution.
A new AI model drafts emergency head CT reports that radiologists cannot tell apart from human work.

Hospitals are finally realizing that relieving doctor burnout is only half the battle if nurses are still drowning in digital paperwork.
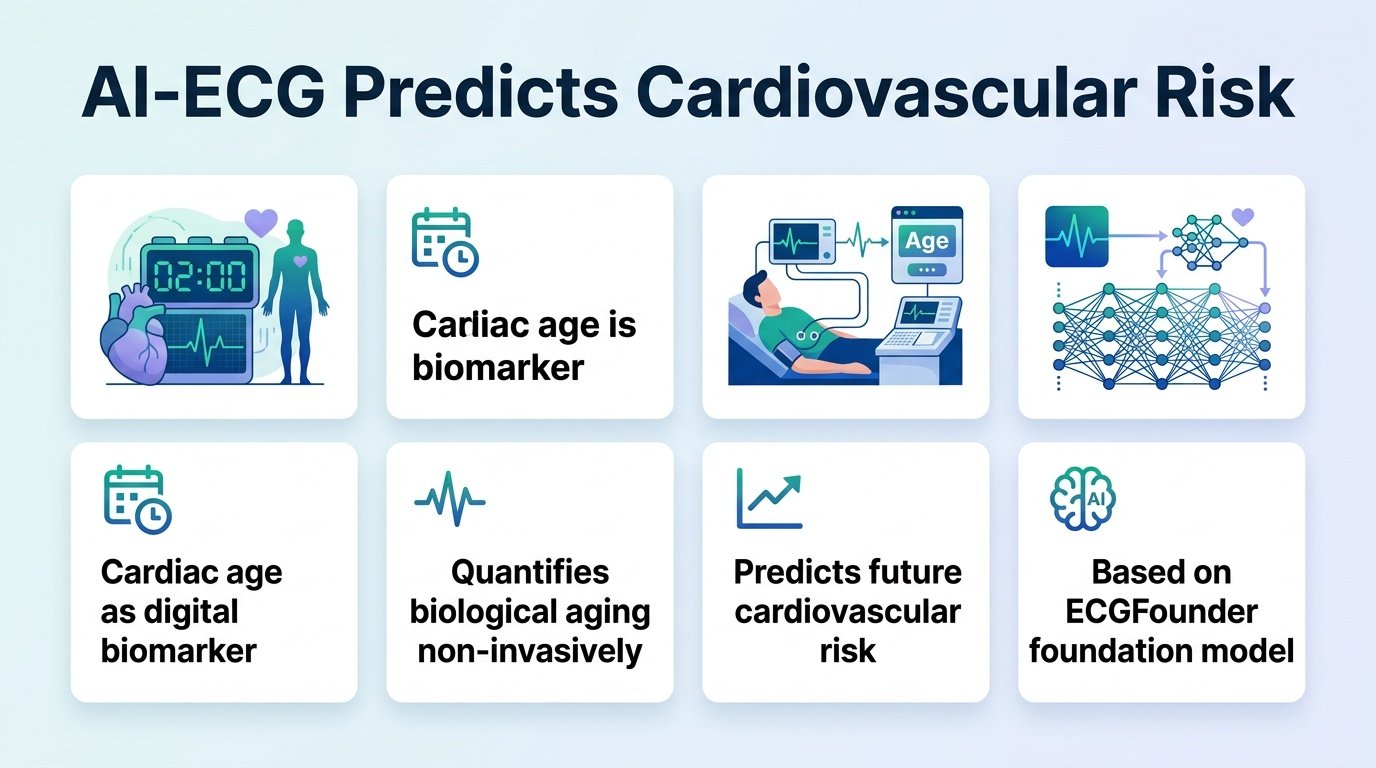
Your calendar age says you are fifty, but a quick heart scan might prove your cardiovascular system is already running on borrowed time.
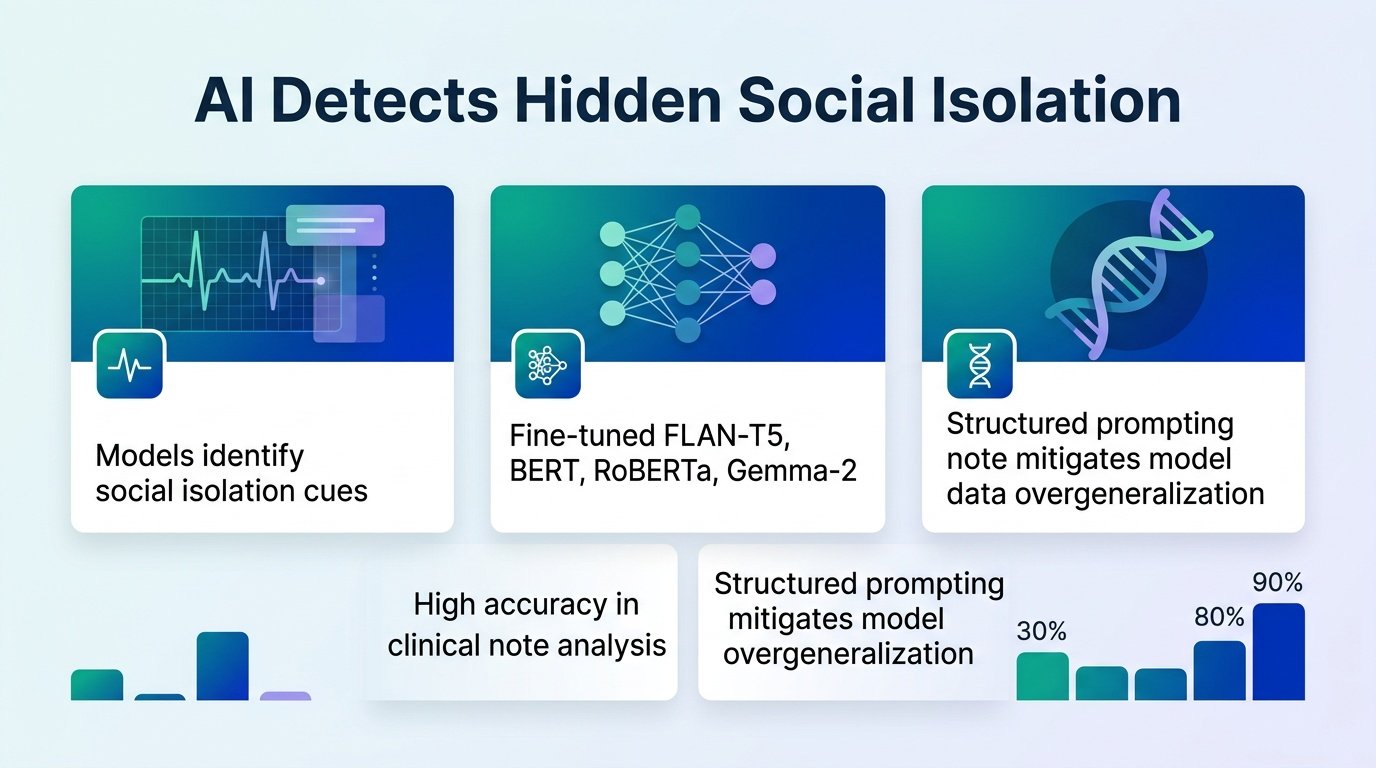
Doctors write down clues about their patients’ loneliness, but those warnings usually sit buried in unstructured text where no one can find them.