
AI passing medical exams cannot save patients
Passing a multiple-choice medical exam does not make an AI safe to treat real patients.

Passing a multiple-choice medical exam does not make an AI safe to treat real patients.
A patient’s fate is often hidden in the messy paragraphs of their medical charts rather than their official disease stage.
A single week of wrist-worn movement data can forecast hundreds of future health conditions years before they are diagnosed.
By tracking entire patient histories instead of clinical snapshots, a new AI model outperforms traditional cancer staging systems across three countries.
A new model bypasses rigid labels to turn raw cardiac waveforms directly into human-readable clinical narratives.
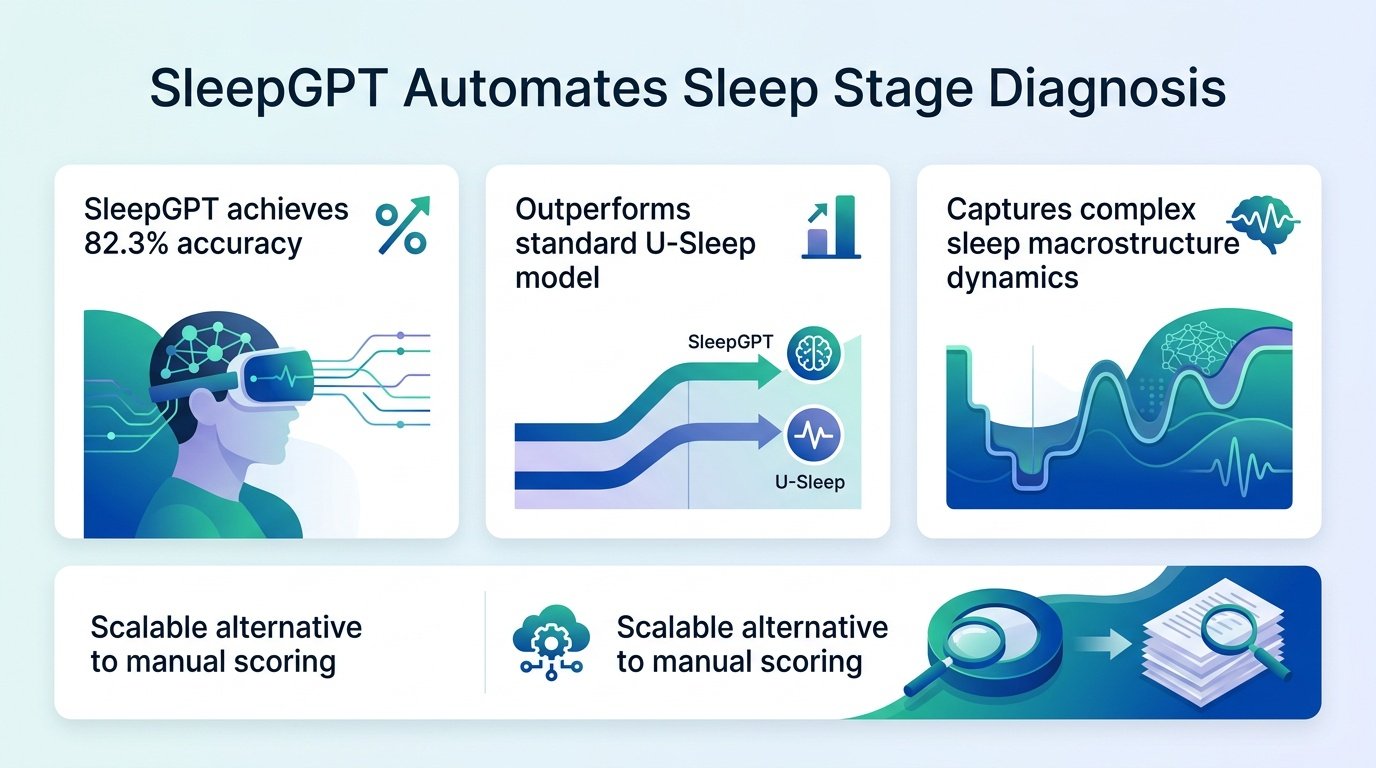
By analyzing the grammar of sleep stages rather than raw brainwaves, a new AI bypasses the need for expensive clinical hardware.
A new foundation model breaks open the black box of medical imaging by forcing AI to show its work through clinical concepts.
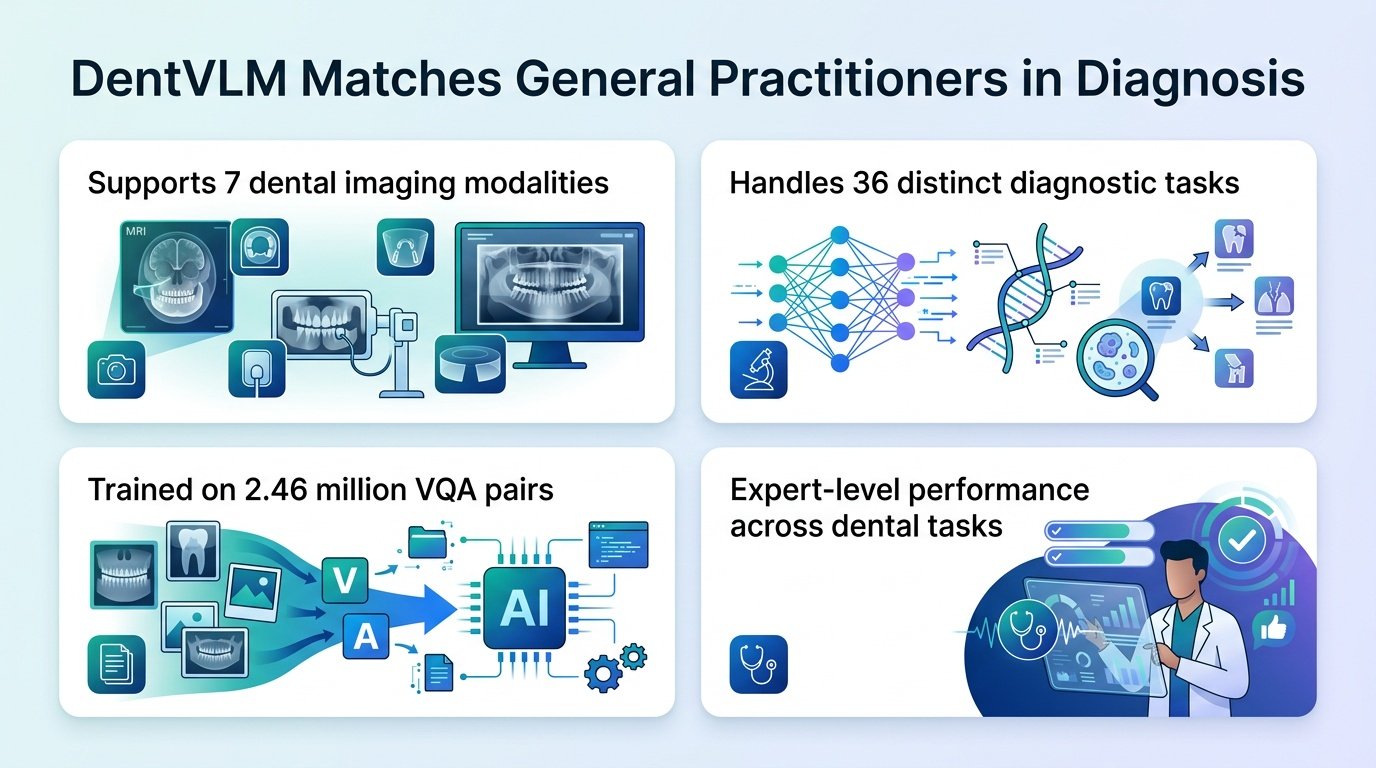
A new multimodal AI model bridges the clinical expertise gap in dentistry by matching the diagnostic accuracy of mid-level practitioners.
Adding medical guidelines to an AI does not make it a better doctor, but teaching it to argue with itself does.
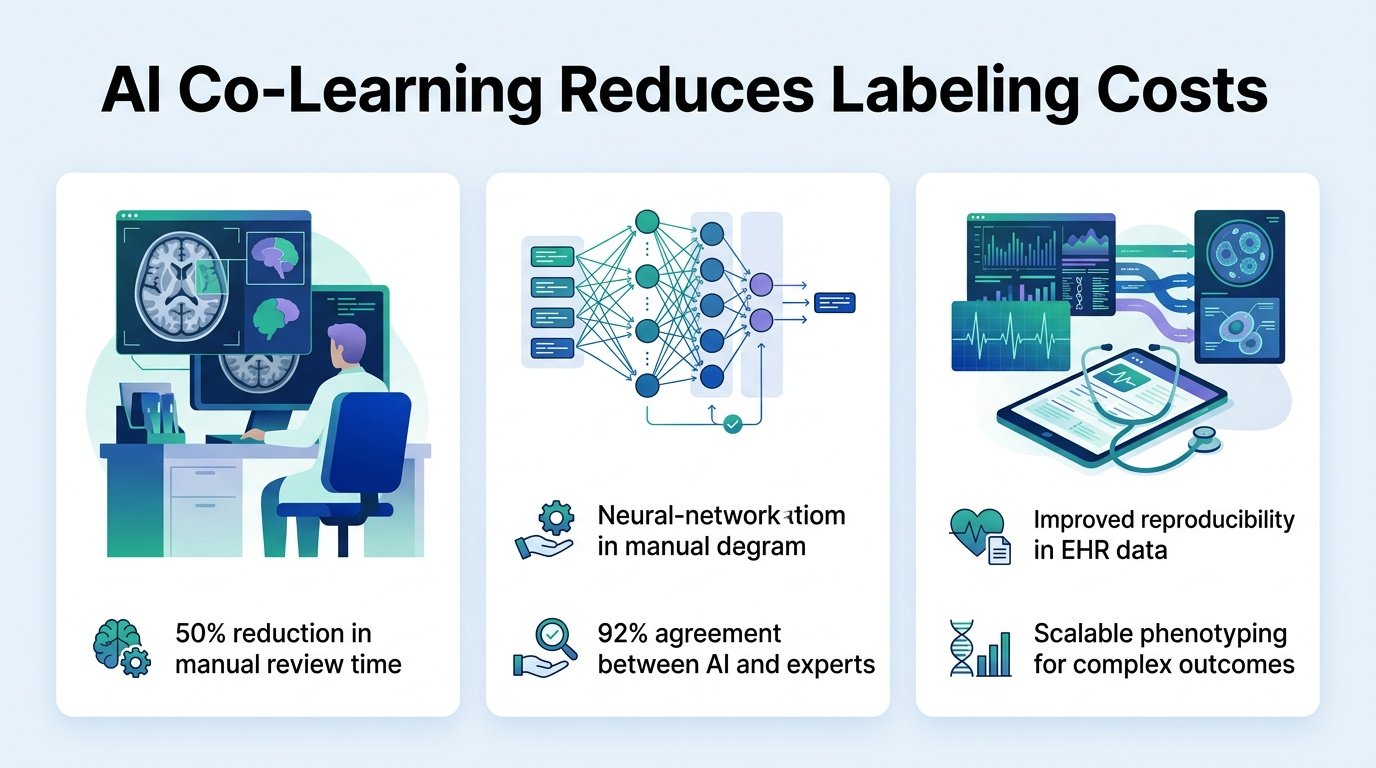
A new human-AI framework shows that the best way to clean up messy electronic health records is to let algorithms and doctors correct each other.