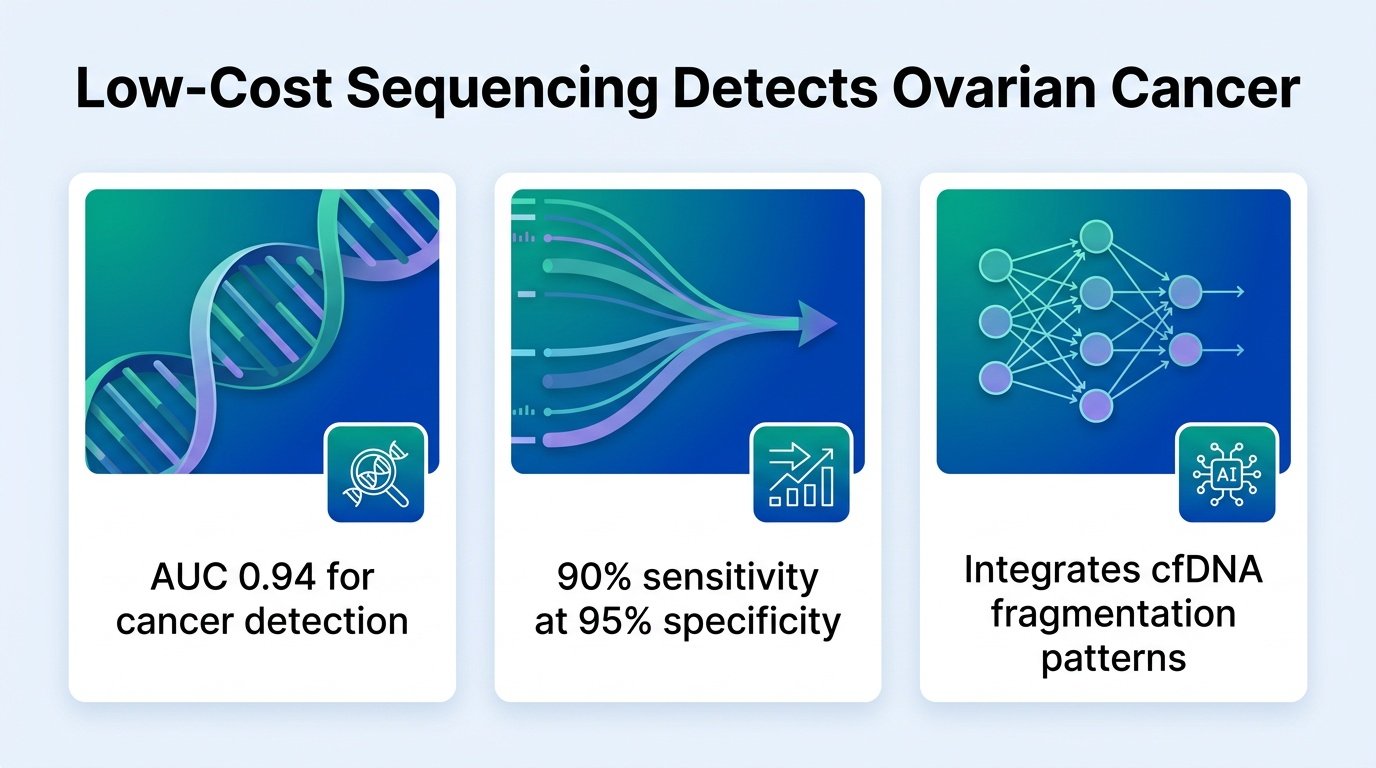
By combining two different genomic signals, researchers proved that cheap, shallow DNA sequencing can catch ovarian cancer with high accuracy.
Can we find ovarian cancer early without spending thousands of dollars per patient on deep genetic sequencing? Liquid biopsies usually rely on deep, expensive sequencing to find tiny traces of tumor DNA. This new study flips that assumption by showing that ultra-low coverage sequencing—which only skims the surface of the genome—can do the job when paired with smart machine learning.
This challenges the industry’s obsession with sequencing depth. Instead of reading every letter of DNA multiple times, we can look at the physical shapes and broad copy-number changes of cell-free DNA fragments. It suggests that the future of cancer screening lies in smarter algorithms, not more expensive lab machines. This shift could finally make population-level screening for ovarian cancer financially viable.
How the models performed
The researchers analyzed plasma cell-free DNA from 85 ovarian cancer patients and 41 cancer-free controls. They used ultra-low coverage whole genome sequencing at just ~1x depth, which is a fraction of the depth used in standard clinical sequencing. From this shallow data, they extracted 21 distinct features capturing both copy number variations and fragmentomic characteristics. They trained an XGBoost model and tested it on an independent cohort comprising 25% of the total patients.
Looking at single features alone was not enough. In the exploratory phase, individual features showed wide overlaps and moderate discriminative power with AUCs ranging from 0.569 to 0.946. The breakthrough came when the researchers stopped treating these genomic signals as isolated metrics and integrated them. The performance metrics on the test set reveal how these signals complement each other:
- The copy-number-only model achieved an AUC of 0.855 with 85% sensitivity but only 50% specificity.
- The fragmentomics-only model reached an AUC of 0.8825 with 95% sensitivity but a poor 30% specificity.
- The integrated model combined both signals to achieve an AUC of 0.900, boosting specificity to 90.00% while maintaining 85.00% sensitivity.
The trade-offs of shallow sequencing
We must be honest about the limitations here. The cohort is small, with only 126 total participants, meaning these high accuracy rates need validation in much larger, diverse populations. Furthermore, the individual models suffered from terrible specificity on their own, meaning a single-focus test would flood clinics with false positives. Ovarian cancer screening requires near-perfect specificity to avoid unnecessary, invasive surgeries on healthy women.
However, the dual-threshold strategy used to define an uncertainty zone is a clever clinical compromise. It acknowledges that shallow sequencing cannot give a perfect yes-or-no answer for every patient. Instead of forcing a guess, it flags borderline cases for follow-up, making it a highly practical screening tool rather than a definitive diagnostic test. This is how we make cancer screening accessible to everyone.
Read the full preprint on medRxiv.