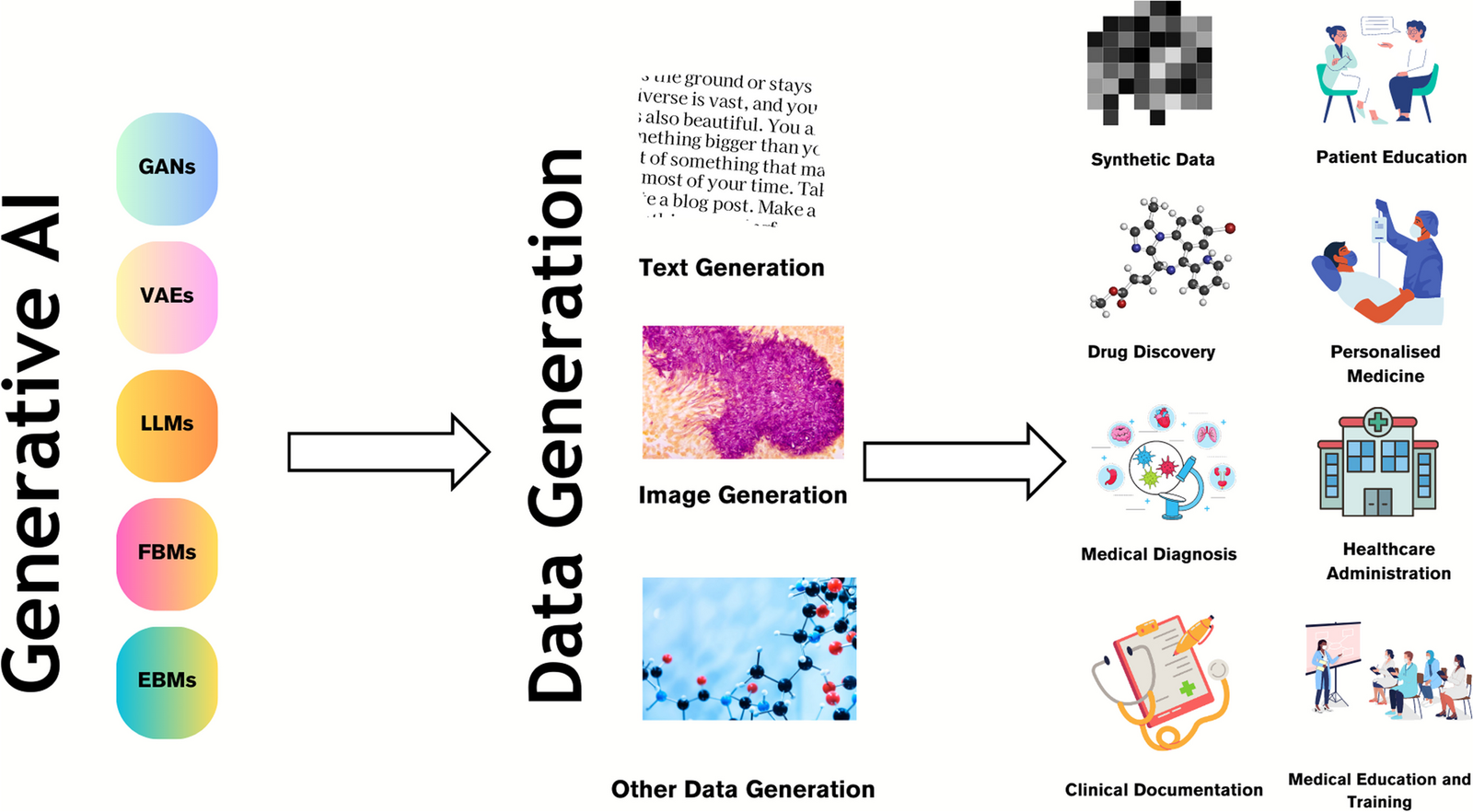
Implication of Bimodal Magnetic Resonance and Fluorescence Imaging Probes in Advanced Healthcare: Enhancing Disease Diagnosis and Targeted Therapy.
Bimodal imaging probes enhance disease diagnosis and therapy, combining MRI and fluorescence for improved precision. 🧬🔬