Automated medical registries promise to slash administrative burdens, but a new trial reveals that large language models are not yet reliable enough to replace human chart reviewers.
How much of a patient’s emergency room record can an algorithm actually understand? Hospitals desperately need to automate the tracking of out-of-hospital cardiac arrests to feed national quality registries. Right now, highly trained clinical staff must manually read through thousands of pages of chaotic, unstructured notes to find key data points.
This is where the automation dream hits a wall.
A new evaluation of an LLM pipeline designed to extract these critical emergency metrics reveals a frustrating paradox. While the AI is highly capable of sorting true cardiac arrests from administrative noise, it stumbles when asked to parse the actual clinical details of the event. This suggests that while AI can help triage records, human clinicians cannot hand over the clipboard just yet.
The sorting success
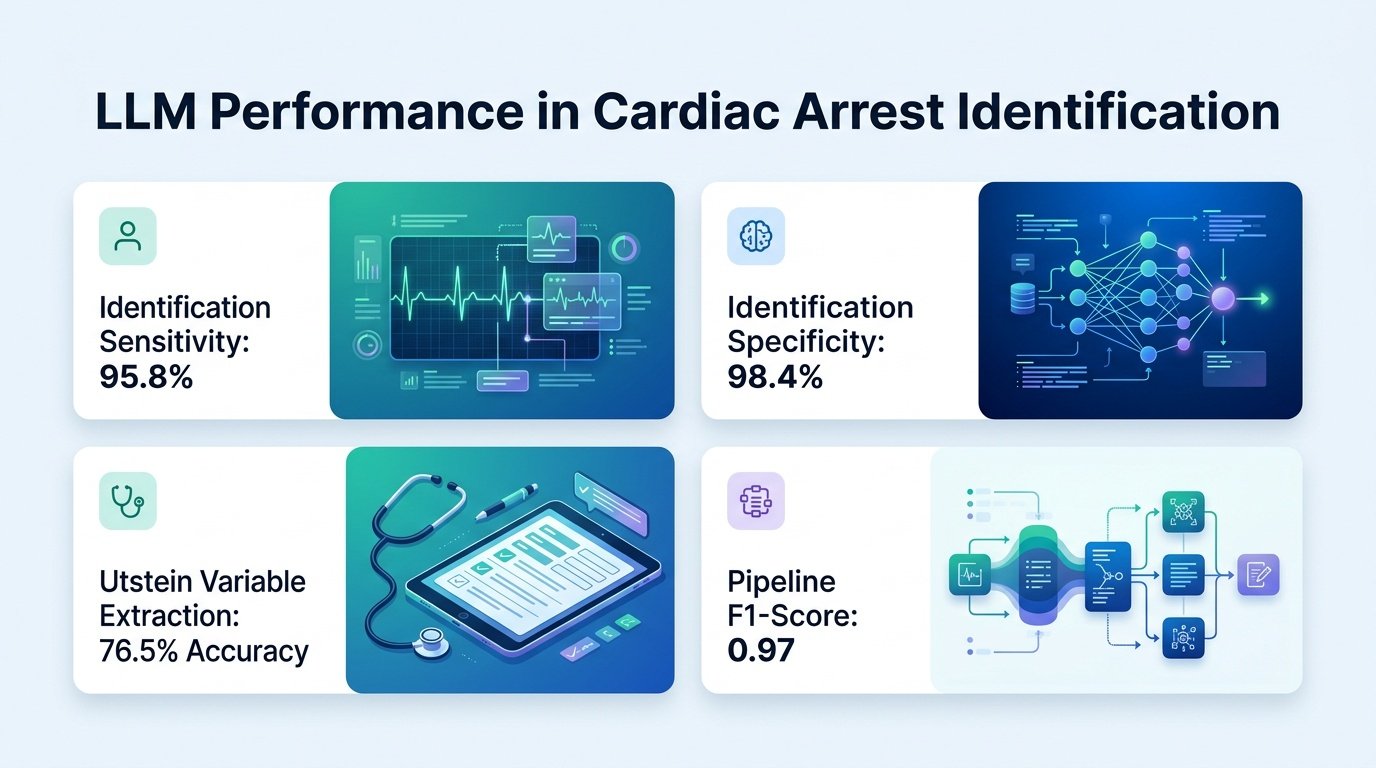
Researchers built a two-module pipeline to analyze ICD-flagged emergency encounters from a large urban health system between 2015 and 2024. They tested the tool against a gold-standard validation sample of 176 cases, which contained 124 true cardiac arrests and 28 non-arrests after physician adjudication.
The first module, built to identify true cardiac arrest cases, performed remarkably well. It achieved an overall accuracy of 0.91 and a positive predictive value of 0.94, easily beating the baseline administrative coding accuracy of 0.82. It also demonstrated a sensitivity of 0.94 and an F1 score of 0.94, though specificity and negative predictive value were lower at 0.75.
The detail dilemma
The real trouble started when the second module tried to extract five standardized Utstein variables from the unstructured text. These variables are the lifeblood of cardiac research, tracking details like whether the arrest was witnessed, the location of the arrest, first recorded rhythm, EMS defibrillation, and bystander response.
The AI’s performance on these metrics was mediocre at best. Accuracy for these variables hovered between a disappointing 0.63 and 0.75, with Cohen’s Kappa scores ranging from a weak 0.31 to a moderate 0.51. The system was particularly bad at identifying bystander response, bottoming out at an accuracy of just 0.63 and a Kappa of 0.31.
- Case identification accuracy reached 0.91 compared to a 0.82 baseline.
- The pipeline achieved a high identification sensitivity of 0.94 but a lower specificity of 0.75.
- Variable extraction accuracy peaked at only 0.75, falling to 0.63 for bystander intervention details.
What to rethink
This performance gap exposes a deeper issue in clinical AI deployment. Identifying a disease state is a simple classification task, but extracting clinical context requires understanding the messy, non-standardized ways doctors write emergency notes. A bystander’s actions might be described in three different sections using highly subjective phrasing, which easily confuses the model.
For now, fully automated registry reporting remains out of reach. The immediate future belongs to hybrid, human-in-the-loop systems where the AI flags the correct charts, but humans verify the details. This still saves time, but it does not eliminate the need for expert staff.
We must also acknowledge the study’s limitations. The pipeline was refined and evaluated on the exact same validation cohort, which likely inflates its real-world performance. Without external validation on completely unseen hospital data, these accuracy rates represent a best-case scenario.
Read the full study in medRxiv.