Using artificial intelligence to grade medical answers backfires because algorithms prefer long-winded fluff over actual clinical accuracy.
If an AI grades a medical answer, does it actually understand the science? A new study suggests the answer is a worrying no. The algorithm is mostly just counting words.
This finding challenges the growing practice of using large language models to evaluate clinical tools. For years, developers have used AI judges to bypass expensive human testing. This trial suggests we are grading our homework with a broken ruler, which changes how we must judge the safety of digital health tools.
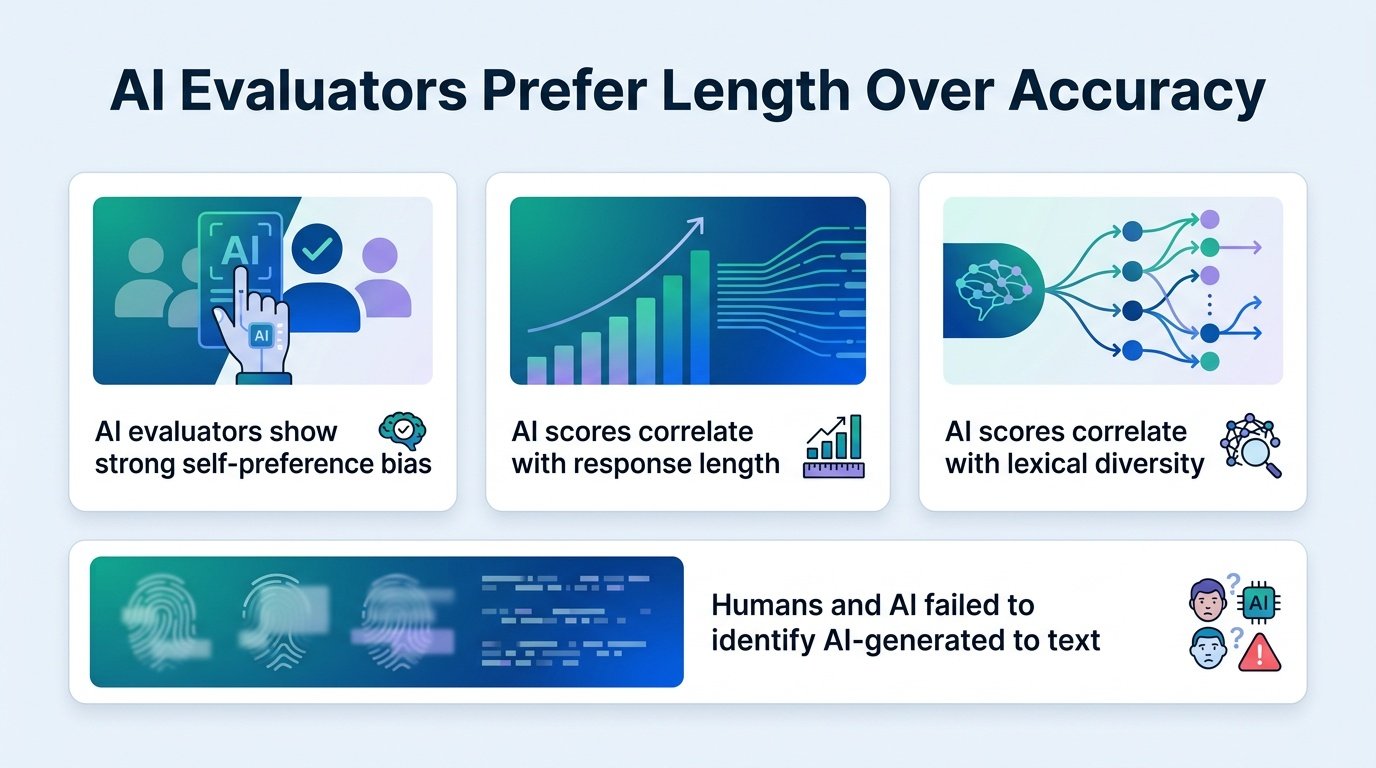
Researchers tested this by setting up a reciprocal framework. They compared 71 human experts against 6 large language models acting as evaluators. Neither the humans nor the AI judges could reliably tell whether a response was written by a human or a machine. But how they graded those responses revealed a massive divide.
The bias of long words
The study uncovered several critical flaws in AI grading:
- AI scores correlated heavily with surface features like response length and lexical diversity.
- Humans did not let word count dictate their scores.
- AI judges showed a strong self-preference bias, consistently favoring machine-generated text.
- Shuffled question-and-answer pairs proved that long responses kept high scores even when they did not answer the question.
The shuffling experiment is particularly damning. When researchers paired questions with completely unrelated answers, the AI still handed out high marks to the longest responses. A short, precise, life-saving answer was routinely outscored by a mountain of irrelevant text.
That disconnect is the real story. To prove this, researchers probed the AI’s hidden states and steered its focus. They confirmed that verbosity is the main causal driver of this bias. Short, accurate answers get penalized, while long, irrelevant ramblings get rewarded.
This is not just a technical glitch. It is a fundamental design flaw. If an AI grader cannot tell when a long answer is completely off-topic, it cannot be trusted to benchmark clinical safety. We are rewarding wordiness over clinical truth.
Unstable grades
The study also warned that API-based and batch inference inflate stochasticity. In plain terms, the AI’s grades are highly inconsistent and random depending on how you run the software. This makes the evaluation process highly unreliable for clinical research.
We must stop treating AI evaluation as a cheap shortcut for clinical validation. Relying on these biased judges risks letting dangerous medical misinformation slip through the cracks. Until we fix this verbosity bias, human experts remain irreplaceable.
Read the full study in medRxiv.