A new foundation model matches or beats human pathologists at grading ulcerative colitis biopsies, potentially solving the clinical trial replication crisis.
How do you prove an experimental drug actually heals a patient’s gut? Right now, drug trials rely on human eyes squinting at tissue slides to calculate complex severity scores. But three different pathologists often yield three different scores, muddying clinical trial results.
This subjectivity stalls drug development. If experts cannot agree on whether a patient is in remission, drug efficacy remains a guessing game. The industry has long tolerated this human bottleneck because no automated alternative could handle the nuance of tissue pathology.
The human bottleneck broken
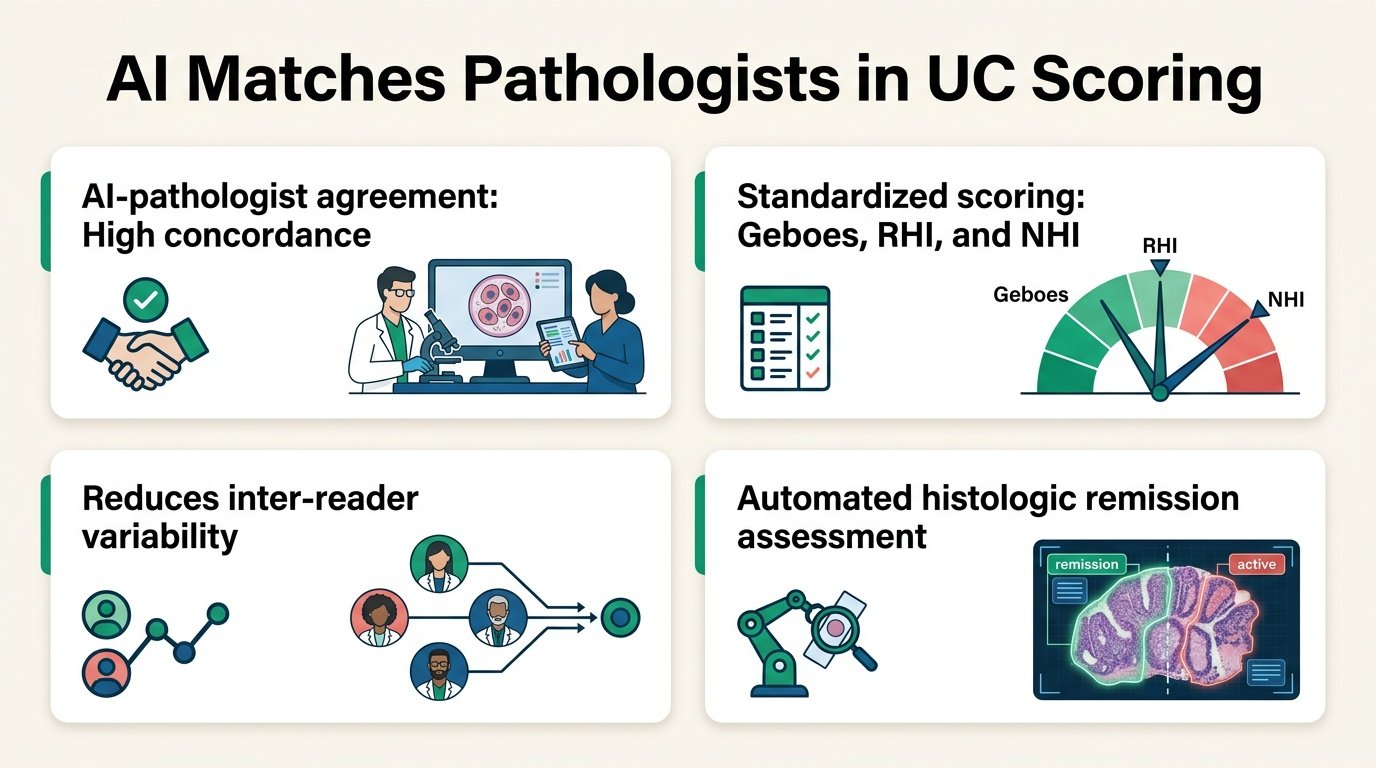
A new preprint introduces AIM-HI UC, an AI tool built on a pathology foundation model called PLUTO. Researchers trained the system on a massive dataset of 10,230 ulcerative colitis biopsies. It predicts individual Geboes subgrades to calculate three major scoring indices: the Geboes Score, the Robarts Histopathology Index (RHI), and the Nancy Histologic Index (NHI).
The data challenges the assumption that human intuition is required for complex tissue grading. In a standalone verification set, the AI achieved non-inferiority against three qualified pathologists across all seven Geboes subgrades, RHI, NHI, and multiple remission thresholds.
More importantly, the AI proved superior to human pathologists in several key areas:
- Superiority in grading Geboes subgrades 0, 1, 2B, and 5.
- Superiority in overall grade-level Geboes and RHI scoring.
- Higher positive percent agreement of 2A histologic remission.
- Greater than 99% repeatability across all examined scoring metrics.
Why consistency matters here
This finding matters because it solves the noise problem in clinical trial data. Human grading is notoriously variable, but this model offers near-perfect repeatability. By standardizing the measurement of mucosal healing, drug developers can finally compare therapies on an identical scale.
The model’s scores also strongly correlated with physical inflammation markers. It matched the proportion of inflamed epithelium (Spearman r=0.83, p<0.01), neutrophils in crypt epithelium (Spearman r=0.83, p<0.01), and mucosal erosion area (Spearman r=0.80, p<0.01).
The road to standardization
There are clear limitations to consider. This tool remains a preprint and has yet to be tested in diverse, real-world clinical practice outside of structured trial datasets. However, the implications are clear. The days of subjective, variable trial endpoints in inflammatory bowel disease are numbered.
Read the full preprint on medRxiv.