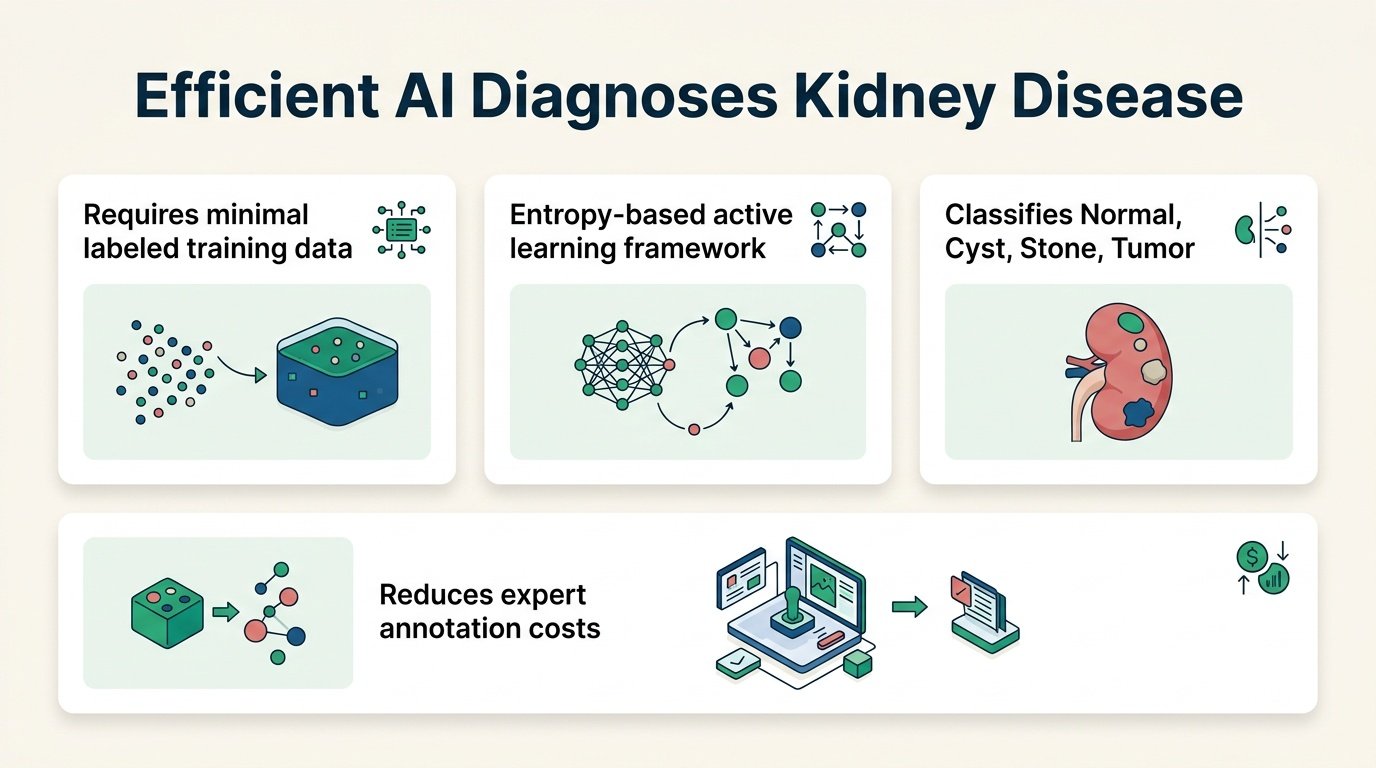
A new active learning model proves that medical AI does not need massive, expensive datasets to outperform human-labeled benchmarks.
How much of a radiologist’s expensive time is wasted labeling obvious medical scans? For years, the consensus was that clinical AI required massive, fully annotated datasets to be safe. This study challenges that brute-force approach. By letting the algorithm choose which images it is most confused by, we can slash expert annotation workloads by over three-quarters.
This shifts the bottleneck of clinical AI from data collection to smart curation. The old playbook of “more data is always better” is dying. Instead, targeted uncertainty is the new currency of machine learning efficiency.
The efficiency payoff
The researchers evaluated their framework on a dataset of 12,446 CT slices, split into 8,716 training, 1,865 validation, and 1,865 test images. Instead of labeling all of them, the system started with just 200 random images. Using a pretrained ResNet-50 backbone, it selected subsequent images based on predictive entropy, focusing only on the most uncertain cases.
The results challenge the necessity of full supervision. After only six query cycles, the model achieved a mean test accuracy of 99.71% ± 0.25% (95% CI: [99.30, 99.94]). It did this using only 2,000 labeled training images. This represents a 77.1% reduction in required annotations, utilizing just 22.9% of the training partition.
This builds on previous efforts to optimize clinical workflows, such as DSAL: Deeply Supervised Active Learning, which tackled segmentation. Similarly, collaborative frameworks like Federated Active Learning have shown how distributed networks benefit from selective labeling. This new kidney classification model proves that the same efficiency applies to diagnostic classification.
Where the model falters
We must be honest about the limitations. The study relies on a single, clean dataset split via stratified sampling. Real-world clinical environments are messy, featuring different scanner models, motion artifacts, and varied patient demographics. While the statistical stability is promising, the model must be tested on external, multi-center datasets before clinical deployment.
- Mean test accuracy of 99.71% with a tight confidence interval.
- A 77.1% reduction in expert labeling requirements.
- Stable performance across five runs (Shapiro-Wilk p = 0.148).
- An uncertainty decay rate of 0.92 and a power-law exponent of 1.2.
If these savings hold up in clinical trials, the cost of developing diagnostic AI will plummet. Hospitals can train highly accurate models locally without hiring armies of annotators. The future of medical AI belongs to the leanest models, not the largest datasets.
Read the full study in Frontiers in Big Data.